March 4, 2026 · News
Why LLMs can't do spatial reasoning at scale, and what models can
Niva extended a published spatial reasoning study from Han et al. (arXiv:2601.05529) by scaling the grid map navigation problem from desk-sized to city-block-sized, then tested 11 frontier LLM variants across five major model families to find where their spatial reasoning breaks. We also ran an ablation that gave the LLMs structured coordinate input instead of raw ASCII, to isolate why they fail.
What the data reveals
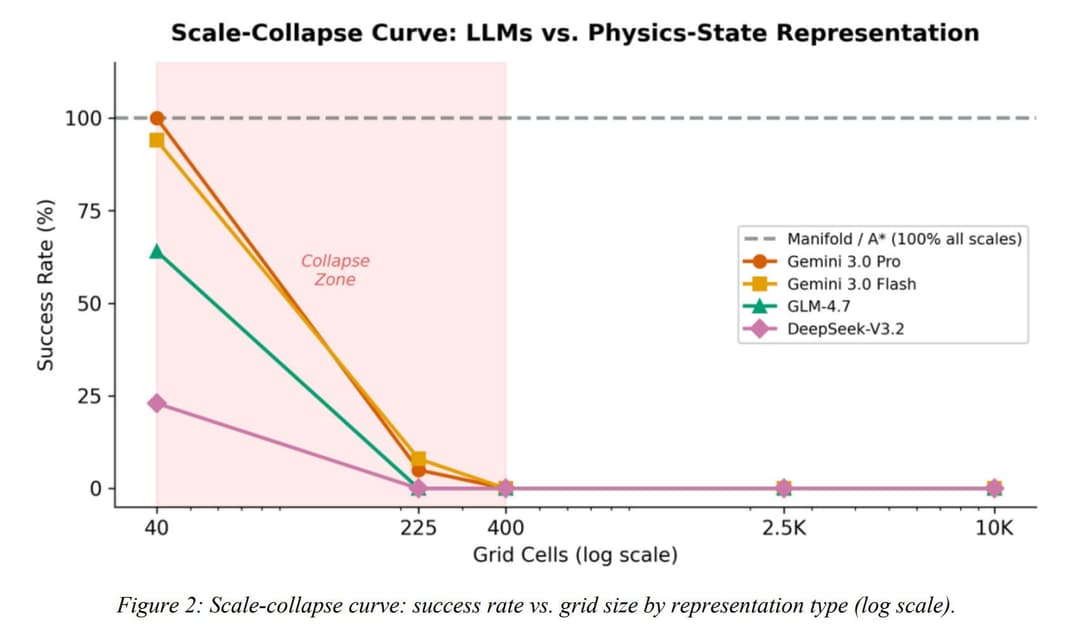
- Manifold and classical graph search (A*, Dijkstra) achieve 100% success at every scale tested, from 40 cells to 2.5 billion cells on a single consumer GPU.
- The best LLM (Gemini 3.0 Pro) achieves 100% only at 8×5 (the size of a desk) and collapses to 0% by 20×20 (the size of a bathroom).
- Claude 4.5 and GPT-5.2 score 0% at every scale, including the smallest.
- With structured coordinate input (parsing removed), Gemini and GPT-5.2 recovered to 100% at minor scales, but still collapsed by 50×50 grids. Claude 4.5 Sonnet stayed at 0% regardless of input format.
- Extended thinking modes (GPT-5.2 low, medium, high) produced zero accuracy improvement at up to 5x latency. More thinking made the problem worse for some models.
Three independent failure modes
The structured-input ablation decomposed LLM spatial failure into three independent factors: parsing burden (removable, accounts for ~90 to 100 percentage points at moderate scales for capable models), spatial coherence limit (architectural, persists with parsed input and produces a sharp phase transition between 400 and 2,500 cells), and model-dependent spatial reasoning deficit (some model families cannot do spatial constraint satisfaction regardless of input format).
The coherence limit is the most architecturally significant. It is a phase transition: sharp, universal across model families, and unresponsive to reasoning amplification. The framework is diagnostic and applies to any model with an auto-regressive transformer backbone, including the vision-language-action models being deployed for robotics today.
Why it matters for embodied AI
Robotics needs spatial understanding. Most robotic AI systems being built today are LLM-based or VLA-based, and they share the architectural property this study tests. The result is consistent across architectures and conditions: auto-regressive token generation is not a reliable substrate for spatial constraint satisfaction at the scales real robots operate in.
Manifold and classical graph search clear the entire scale range tested, on hardware that costs less than $2,000. On uniform grids, A* matches Manifold's accuracy at lower computational cost. The physics-native advantage shows up where the grid stops being uniform: heterogeneous terrain, partial observability, physical uncertainty, and continuous sensor integration, none of which this study exercises but all of which are properties of real robotic deployment.
The deployment question
The question is not how to fix LLMs for spatial reasoning. It is why you would try, when deterministic alternatives exist that solve the problem at scale, run on commodity hardware, and extend cleanly to the messier conditions real robots actually face.
The full technical report is available on the Research page: https://www.nivatech.io/research/research-spatial-constraint-satisfaction-does-not-scale-in-auto-regressive-models
One architecture, multiple domains
Manifold wasn't designed for grid navigation specifically. It was built around constitutive physics that runs continuously and a deterministic world model that handles whatever sensor data and constraint structure the problem provides. Grid navigation exercises one slice. Pathfinding on a real robot exercises another. The result is the same in both: deterministic guarantees, scale-invariant accuracy, real-time evaluation.